 2022, Vol. 49
2022, Vol. 49文章信息
引用本文 |

基金项目
- 国家自然科学基金(61702196)
作者简介
- 李西明(1974—),男,博士,副教授,研究方向为人工智能相关领域,E-mail:liximing@scau.edu.cn.
通讯作者
- 高月芳(1979—),女,博士,副教授,研究方向为计算机视觉、机器学习相关领域,E-mail:gaoyuefango@scau.edu.cn.
文章历史
- 收稿日期:2021-08-31



【研究意义】鸡群均匀度是判断当前鸡群生长情况的一个重要指标,可描述鸡只在育成过程中是否正常生长。计算鸡群均匀度需要对肉鸡进行称重,传统测量肉鸡体重的方法存在难度大、误差大、费时耗力等缺点,而且会增加肉鸡的应激反应,应激严重时还会导致肉鸡死亡,因此自动化和智能化计算鸡群均匀度成为当务之急。为解决这一问题,首先需要开展基于计算机视觉的肉鸡图像分割研究。
【前人研究进展】传统二维图像的信息量已不能满足精准图像分割的需求,人们开始把研究重点放在信息量更大的三维图像上[1-3]。其中,深度图像(depth image)是一类特殊形式的图像,成像获得的是二维图像,即伪彩色图,但沿摄像机光轴方向的深度信息存储在深度图像的像素点中,而普通二维图像则缺失这部分深度信息。深度图像的成像方式与传统光学图像不一样,主要由光源、深度相机和物体三者的相互位置和运动情况所决定。从20世纪70年代开始,相关领域的研究人员不断尝试研究图像分割技术,而最早应用图像分割技术的是医学影像处理领域,该领域通过基于阈值[4-8]的简单方法进行粗糙像素级别的分割。随着需求的增加,图像分割场景逐渐复杂,对分割技术的要求也越来越高,陆续出现了基于边缘[9-14]、区域[15-16]、聚类[17-21]等的分割方法,这些方法的应用使得复杂场景下的分割效果得到改善。而近年随着深度学习的迅速发展,一些学者使用深度学习[22-32]进行图像分割,并提出了许多有效、准确的图像分割模型,如全卷积网络FCN[22]、U-net[23]、金字塔场景解析网络(Pyramid Scene Parsing Network,PSPNet)[24]、DeepLab[25-28]、Mask R-CNN[29]等,这些模型的出现不但提高了图像分割的准确度,而且使分割过程更加便捷。
【本研究切入点】前人研究对肉鸡图像的分割主要采用二维图像,主要研究方法包括颜色空间转换、肉鸡背景分割、形态学处理、噪声过滤、提取特征、阈值选择等。这些方法并没有考虑图像本身的语义信息,使得分割场景复杂的图像非常困难。本研究基于深度学习提出一种能快速、准确实现肉鸡深度图像端到端分割的方法,无需阈值分割、去噪等繁琐的图像处理过程。【拟解决的关键问题】本研究对收集的4 058张深度图像制作成肉鸡深度图数据集,并采用FCN、U-net、PSPNet、DeepLab、Mask RCNN等5个图像分割模型对上述数据集进行试验,分析不同图像分割方法对肉鸡深度图像的分割效果与性能,根据准确率、精确率、召回率、调和平均数和交并比5个指标对不同图像分割方法进行比较与评价。
1 材料与方法 1.1 试验材料1.1.1 数据采集 试验使用英特尔RealSense D435i深度相机分别于2020年11月20日、12月3日,2021年1月12日、29—30日、2月6日5个时间段在广东省新兴县簕竹镇非雷村试验鸡场,采集一批现实场景中的肉鸡深度图像。采集方法有两种:(1)单只鸡放在简易鸡笼中以分辨率为1 280×720的标准进行拍照;(2)以帧率为6、分辨率为1 280×720的标准拍摄视频,并从视频中以每2 s 1帧的频率截取深度图像。
对采集的肉鸡深度图像按照图 1A流程构建深度图数据集。最终得到的肉鸡深度图集包含238只不同肉鸡共4 058张标注完备的深度图像,肉鸡深度图数据集结构的格式如图 1B所示,通过标注肉鸡的轮廓生成标注文件,以.jpg格式存储。肉鸡深度图数据集中的数据种类非常丰富,包括不同背景、光照强度、拍摄角度下的不同品种、日龄、姿势形态的肉鸡(图 2)。

|
| 图 1 肉鸡深度图数据集构建流程(A)及结构(B) Fig. 1 Construction process (A) and structure (B) of broiler depth map data set |

|
| A:不同拍摄角度;B:不同姿势形态;C:不同肉鸡数量 A: Different shooting angles; B: Different postures; C: Different number of broilers 图 2 肉鸡深度图数据集 Fig. 2 Broiler depth map dataset |
1.1.2 数据集处理 拍摄过程中肉鸡不停运动,存在姿势各异、遮挡严重、拍摄不全等情况,剔除在图像边缘拍摄不完整的肉鸡,不对其进行标注。采用CVAT软件对肉鸡深度图像进行标注。为了达到理想的分割结果,人工标注肉鸡边界轮廓时,将肉鸡深度图像放大到极限后再进行细致的标注(图 3),平均每只鸡的轮廓有300~500个标注点。标注完成后,将生成的标注图(存储格式为.jpg)、json点标签文件(包含各个点的坐标)以及原深度图像导出。

|
| 图 3 肉鸡深度图像标注细节 Fig. 3 Labeling details of broiler depth map |
1.2 试验方法
将肉鸡深度图数据集中的训练集用于训练分别以FCN、U-Net、PSPNet、DeepLab、Mask R-CNN等5种神经网络为骨干网络的分割模型,然后将测试集输入到训练好的分割模型中,得到单只鸡的图像。具体流程见图 4。

|
| 图 4 肉鸡深度图像分割流程 Fig. 4 Segmentation process of broiler depth map |
为了客观、准确地评估和比较上述5种模型对肉鸡深度图集分割的效果,统一使用肉鸡深度图数据集进行试验,其中训练集︰验证集︰测试集=6 ︰ 2 ︰ 2,并采用准确率(Accuracy,A)、精确率(Precision,P)、召回率(Recall,R)、调和平均数(F1)和交并比(Intersection Over Union,IOU)作为肉鸡深度图集分割效果的衡量指标。计算公式如下:
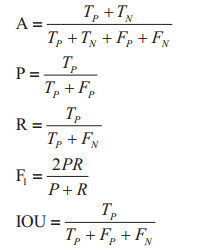
|
式中,TP表示图像中正确预测肉鸡的像素数,TN表示图像中正确预测背景的像素数,FP表示图像中将背景预测为肉鸡的像素数,FN表示图像中将肉鸡预测为背景的像素数。
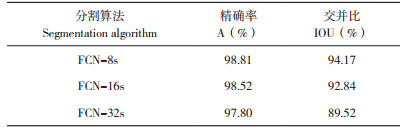
2 结果与分析 2.1 FCN模型对肉鸡深度图像的分割结果根据所使用池化层的不同,FCN模型可分为FCN-32s、FCN-16s、FCN-8s等3种类型。表 1为不同FCN模型在肉鸡深度图集上分割的准确率和交并率,采用不同FCN模型对同一图像进行分割的结果(图 5)显示,FCN模型的分割效果并不理想,没有考虑图像上下文信息,且由于像素点间的关联性较低,导致目标边界模糊。

|
| 图 5 不同FCN模型对肉鸡深度图像的分割效果 Fig. 5 Segmentation effects of broiler depth map by different FCN models |
2.2 U-Net模型对肉鸡深度图像的分割结果
采用U-net模型对肉鸡深度图像进行分割,结果(图 6)显示,分割后的图像中能明显将前景目标切割出来,且目标边缘轮廓清晰,说明该模型能够实现细粒度的分割。

|
| 图 6 U-Net模型对肉鸡深度图像的分割效果 Fig. 6 Segmentation effects of broiler depth map by U-Net model |
2.3 PSPNet模型对肉鸡深度图像的分割结果
采用PSPNet模型对肉鸡深度图像进行分割,结果(图 7)显示,虽然能够较好地将前景目标分割出来,但是对目标边缘分割的处理较为模糊,导致目标边缘较为圆滑,不够精细。

|
| 图 7 PSPNet模型对肉鸡深度图像的分割效果 Fig. 7 Segmentation effects of broiler depth map by PSPNet model |
2.4 DeepLab模型对肉鸡深度图像的分割结果
采用Deeplab模型目前最新的版本DeepLabv3+ 对肉鸡深度图像进行分割,由图 8可知,虽然DeepLab-v3+ 能够明显区分出前景目标和背景,肉鸡轮廓清晰,但是相比于标注图,边缘部分的细节没能准确分割出来。

|
| 图 8 DeepLab-v3+ 模型对肉鸡深度图像的分割效果 Fig. 8 Segmentation effects of broiler depth map by Deeplab-v3+ model |
2.5 Mask R-CNN模型对肉鸡深度图像的分割结果
采用Mask R-CNN模型对肉鸡深度图像进行分割,结果(图 9)显示,该模型能够精确识别不同数量的肉鸡并分割出来,每只肉鸡的轮廓清晰,边缘处理非常细致。

|
| 图 9 Mask R-CNN模型对肉鸡深度图像的分割效果 Fig. 9 Segmentation effects of broiler depth map by Mask R-CNN model |
2.6 不同模型对肉鸡深度图像分割结果的比较
从上述不同模型的分割效果(表 2)可见,Mask R-CNN模型对肉鸡深度图像的分割效果最佳,其调和平均数F1为95.03%,交并比IOU为94.69%,其分割精度细,能够清晰地将肉鸡从深度图像中分割出来,并且对目标边缘分割的处理较为细致,分割得到肉鸡轮廓明显;FCN-8s模型的分割效果仅次于Mask R-CNN模型,其准确率A为98.81%,调和平均数F1为94.58%,交并比IOU为94.17%,并且其精确率P在5个模型中最高,为95.78%;而PSPNet模型虽然能够将局部与全局的信息融合一起,分割精度细,能够清晰地将肉鸡从深度图像中分割出来,但存在对目标边缘分割处理较为粗糙的缺点;而U-Net模型虽能够实现像素级别的分割,分割得到的目标轮廓清晰,分割准确度A高达97.99%,但是交并比IOU则较低,仅有89.62%;DeepLab v3+ 模型的IOU最低,仅为58.23%,虽然其对目标边缘分割的准确度高于PSPNet,但相比于Mask R-CNN模型,其对边缘部分仍有一些细节没有准确分割出来,这会影响后续对分割后图像的研究效果。

|
综上,Mask R-CNN模型对肉鸡深度图像的分割效果最佳,其准确率、召回率、调和平均数以及交并比均最高,对肉鸡的边缘部分分割最准确。因此后续研究将主要使用Mask R-CNN模型作为分割模型,并且增加模型训练数据集的多样性,包括肉鸡品种、日龄、光线等,以提高模型识别和分割性能。
3 讨论本研究针对在复杂环境背景汇总难以识别分割多只肉鸡的问题,使用FCN、U-Net、PSPNet、DeepLab、Mask R-CNN 5种经典、热门的分割算法对肉鸡深度图像集进行分割试验,探讨基于深度学习实现对多只肉鸡深度图分割的方法。其中,FCN引领了将深度学习应用于图像分割的潮流,其与CNN不同之处在于模型的最后没有使用全连接层,而是以全卷积的方式实现整个模型。为了实现全卷积,Long等[22]主要采用卷积化、上采样和跳层连接3种技术:卷积化即是将普通分类网络的全连接层换成对应的卷积层;上采样就是反卷积,由于经池化操作图片尺寸会缩小,而图像语义分割的输出分割图一般要与输入图像尺寸相同,因此需要进行上采样,也就是卷积的反向传播;跨层连接的主要作用是优化结果,将不同池化层的结果进行上采样后优化输出。但FCN的网络结构相对较大,对图像的细节不够敏感,且仅对各个像素进行分类,没有考虑到像素间的关系,缺乏空间一致性,此外分割并非实例级别,效率也不够实时,因此,很少有人将FCN应用在具有复杂信息的深度图像分割上。
为了解决FCN在效率上不够及时的问题,Ronneberger等[23]在FCN的基础上进行改进,创建出端到端全卷积网络U-Net,其具有两个优点:一是局部感知能力,二是用于训练的样本远大于训练图像的数量。其网络架构主要由用于捕捉语义的收缩路径和用于精确定位的扩展路径组成,整个网络共有23个卷积层。
PSPNet能弥补FCN缺乏空间一致性的缺陷,具有理解全局语境信息的能力,能充分利用全局信息,从而有效地在场景分析任务中产生高质量的结构,并且为像素级预测提供优越的框架。PSPNet在场景解析和语义分割任务中能够融合合适的全局特征,将局部和全局信息融合一起,并提出一个适度监督损失的优化策略,在多个数据集上表现优异。
Deeplab系列是由谷歌团队提出的,主要针对语义分割任务而设计,其结合了深度卷积神经网络、概率图模型、空洞卷积、全连接条件随机场、多尺度预测等方法,改进语义分割的效果。目前Deeplab系列已有4个版本,分别是Deeplab v1[25]、Deeplab v2[26]、Deeplab v3[27]和Deeplab v3+[28]。
Mask R-CNN由何凯明等[29]基于Faster R-CNN[32]改进的用于图像分割的深度卷积网络,可以用来完成目标分类、目标检测、实例分割等计算机视觉任务。虽然Mask R-CNN的大体框架仍是Faster R-CNN的框架,在基础特征网络之后加入了全连接的分割子网,但Faster R-CNN添加了一个预测分割Mask的分支以实现实例分割,并将ROI Pooling层替换成ROI Align层以提高实例分割的准确率。不同于用于语义分割的FCN、U-Net、PSPNet和DeepLab等模型,Mask R-CNN的功能更强大,还可以实现实例分割。语义分割可以识别图像中属于同一类的目标以及位置,而实例分割还可以区分同一类目标中的不同个体。
从FCN、U-Net、PSPNet、DeepLab、Mask R-CNN等模型对肉鸡深度图像分割的试验结果可知,语义分割并不适用于包含多只肉鸡的深度图像分割,虽然FCN、U-Net、PSPNet、DeepLab模型的准确率分别有98.81%、97.99%、98.02%、86.38%,即对像素级别分类非常准确,但当多只肉鸡之间互相有遮挡时,分割出来完全看不出是一只鸡的形状,这对后续应用(如单只肉鸡体重预测)作用不大。而使用Mask R-CNN则可解决问题,即采用实例分割,肉鸡之间出现遮挡的情况,被遮挡到的肉鸡分割出来的形状不完整,对于这些残缺的肉鸡形状,应该根据实际生产环境的需求而作取舍决定,例如如果后续用其来预测肉鸡体重,则应将其舍弃,否则可能会影响到整个鸡群的均匀度。
此外,虽然本研究中Mask R-CNN模型对多只肉鸡深度图像的分割表现最佳且达到实际生产环境的要求,但Mask R-CNN并非当前最新、性能最好的分割模型,后续将会加入其他分割模型进行研究对比,如目前受到广泛关注的基于Transformer[33]的分割模型,以及研究各种基于深度学习的图像分割算法与传统的图像分割算法(基于阈值、边缘[4-8]、区域[9-14]、聚[15-16]类[17-21]等)结合在肉鸡深度图集上的表现。
4 结论本研究分析了基于深度学习的图像分割算法在肉鸡深度图集上的性能表现,对从广东省新兴县非雷试验鸡场多批次收集的4 058张深度图像采用CVAT软件进行标注,以训练集︰验证集︰测试集=6 ︰ 2 ︰ 2的比例制作成肉鸡深度图数据集。基于Mask R-CNN模型对肉鸡深度图像进行识别与分割,能够精准识别并分割复杂环境下的多只肉鸡,分割准确率为98.96%,交并比为94.69%,基本上能满足生产实际中的肉鸡识别与分割要求。与FCN、U-Net、PSPNet、DeepLab模型相比,Mask R-CNN模型对多只肉鸡深度图像分割效果的各项评价指标(准确率、召回率、调和平均数以及交并比)均最佳,说明在复杂的生产环境中,Mask R-CNN肉鸡分割模型具有较好的识别分割效果。
| [1] |
GUO C, LI C, GUO J, CONG R, FU H, HAN P. Hierarchical features driven residual learning for depth map super-resolution[J]. IEEE Transactions on Image Processing, 2019, 28(5): 2545-2557. DOI:10.1109/TIP.2018.2887029 |
| [2] |
ZHANG H, ZHANG Y, WANG H L, HO Y S, FENG S Z. Wldisr: weighted local sparse representation-based depth image super-resolution for 3D video system[J]. IEEE Transactions on Image Processing, 2019, 28(2): 561-576. DOI:10.1109/TIP.2018.2866959 |
| [3] |
WEN Y, SHENG B, LI P, LIN W Y, FE NG, D D. Deep color guided coarse-to-fine convolutional network cascade for depth image super-resolution[J]. IEEE Transactions on Image Processing, 2019, 28(2): 994-1006. DOI:10.1109/TIP.2018.2874285 |
| [4] |
OSTU N. A threshold selection method from gray-level histograms[J]. IEEE Transactions on Systems, Man, and Cybernetics, 1979, 9(1): 62-66. DOI:10.1109/TSMC.1979.4310076 |
| [5] |
KAPUR J N, SAHOO P K, WONG A K C. A new method for gray-level picture thresholding using the entropy of the histogram[J]. Computer Vision, Graphics, and Image Processing, 1985, 29(3): 273-285. DOI:10.1016/S0734-189X(85)90156-2 |
| [6] |
SRIKANTH R, BIKSHALU K. Multilevel thresholding image segmentation based on energy curve with harmony search algorithm[J]. Ain Shams Engineering Journal, 2020, 12(1): 1-20. DOI:10.1016/j.asej.2020.09.003 |
| [7] |
YEN J C, CHANG F J, CHANG S. A new criterion for automatic multilevel thresholding[J]. IEEE Transactions on Image Processing, 1995, 4(3): 370-378. DOI:10.1109/83.366472 |
| [8] |
YU T, XU S, ZHOU X, XIAO J, ZHANG B. Semi-automatic extraction of the threshold segmentation of coastline based on coastline type[J]. IOP Conference Series: Earth and Environmental Science, 2021, 690(1): 12012-12019. DOI:10.1088/1755-1315/690/1/012019 |
| [9] |
KHAN J F, BHUIYAN S M, ADHAMI R R. Image segmentation and shape analysis for road-sign detection[J]. IEEE Transactions on Intelligent Transportation Systems, 2011, 12(1): 83-96. DOI:10.1109/TITS.2010.2073466 |
| [10] |
ROSENFELD A. The max roberts operator is a hueckel-type edge detector[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 1981, 3(1): 101-103. DOI:10.1109/TPAMI.1981.4767056 |
| [11] |
LANG Y, ZHENG D. An improved sobel edge detection operator//Proceedings of the 2016 6th International Conference on Mechatronics, Computer and Education Informationization(MCEI 2016)[C]. Shenyang: Atlantis Press, 2016: 590-593.
|
| [12] |
YANG L, WU X, ZHAO D, LI H, ZHAI J. An improved Prewitt algorithm for edge detection based on noised image//2011 4th International Congress on Image and Signal Processing[C]. Shanghai: IEEE, 2011: 1197-1200.
|
| [13] |
ULUPINAR F, MEDIONI G. Refining edges detected by a log operator[J]. Computer Vision, Graphics, and Image Processing, 1990, 51: 275-298. DOI:10.1016/0734-189X(90)90004-F |
| [14] |
LI E S, ZHU S L, ZHU B S, ZHAO Y, XIA C G, SONG L H. An adaptive edge-detection method based on the canny operator//2009 International Conference on Environmental Science and Information Application Technology[C]. Wuhan: IEEE, 2009: 465-469.
|
| [15] |
ZHANG Y J. An overview of image and video segmentation in the last 40 years[J]. Advances In Image and Video Segmentation, 2006, 1-16. DOI:10.4018/978-1-59140-753-9.ch001 |
| [16] |
TREMEAU A, BOREAL N. A region growing and merging algorithm to color segmentation[J]. Pattern Recognition, 1997, 30: 1191-1203. DOI:10.1016/S0031-3203(96)00147-1 |
| [17] |
CHENG Y. Mean shift, mode seeking, and clustering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1995, 17(8): 790-799. DOI:10.1109/34.400568 |
| [18] |
FUKUNAGA K, HOSTETLER L. The estimation of the gradient of a density function, with applications in pattern recognition[J]. IEEE Transactions on Information Theory, 1975, 21: 32-40. DOI:10.1109/TIT.1975.1055330 |
| [19] |
LEVINSHTEIN A, STERE A, KUTULAKOS K N, FLEET D J, DICKINSON S J, SIDDIQI K. Turbopixels: fast superpixels using geometric flows[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(12): 2290-2297. DOI:10.1109/TPAMI.2009.96 |
| [20] |
ZHANG X F, SUN Y J, LIU H, HOU Z J, ZHAO F, ZHANG C M. Improved clustering algorithms for image segmentation based on non-local information and back projection[J]. Information Sciences, 2021, 550: 129-144. DOI:10.1016/j.ins.2020.10.039 |
| [21] |
WEI D, WANG Z B, SI L, TAN C, LU X L. An image segmentation method based on a modified local-information weighted intuitionistic fuzzy c-means clustering and gold-panning algorithm[J]. Engineering Applications of Artificial Intelligence, 2021, 101: 104209. DOI:10.1016/j.engappai.2021.104209 |
| [22] |
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(4): 640-651. DOI:10.1109/CVPR.2015.7298965 |
| [23] |
RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation//International Conference on Medical image computing and computer-assisted intervention[C]. Cham: Springer, 2015: 234-241.
|
| [24] |
ZHAO H S, SHI J P, QI X J, WANG X G, JIA J Y. Pyramid scene parsing network//Proceedings of the IEEE conference on computer vision and pattern recognition[C]. Hawaii: IEEE, 2017: 2881-2890.
|
| [25] |
CHEN L C, PAPANDREOU G, KOKKINOS I, MURPHY K, YUILLE A L. Semantic image segmentation with deep convolutional nets and fully connected crfs[J]. Computer Science, 2014(4): 357-361. DOI:10.1080/17476938708814211 |
| [26] |
CHEN L C, PAPANDREOU G, KOKKINOS I, MURPHY K, YUILLE AL. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. DOI:10.1109/TPAMI.2017.2699184 |
| [27] |
CHEN L C, PAPANDREOU G, SCHROFF F, ADAM H. Rethinking atrous convolution for semantic image segmentation[EB/OL]. [2022-1-24]https://arxiv.org/abs/1706.05587.
|
| [28] |
CHEN L C, ZHU Y K, PAPANDREOU G, SCHROFF F, ADAM H. Encoder-decoder with atrous separable convolution for semantic image segmentation//Proceedings of the European Conference on Computer Vision(ECCV)[C]. Munich: Springer, 2018: 801-818.
|
| [29] |
HE K M, GKIOXARI G, DOLLAR P, GIRSHICK R. Mask R-CNN[J]. IEEE Trans Pattern Anal Mach Intell, 2020, 42(2): 386-397. DOI:10.1109/TPAMI.2018.2844175 |
| [30] |
HE K M, ZHANG X Y, REN S Q, SUN J. Deep residual learning for image recognition//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR)[C]. Las Vegas: IEEE, 2016: 770-778.
|
| [31] |
SZEGEDY C, LIU W, JIA Y Q, SERMANET P, REED S ANGUELOV D, ERHAN D, VANHOUCKE V, RABINOVICH A. Going deeper with convolutions//2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR)[C]. Boston: IEEE, 2015: 1-9.
|
| [32] |
REN S Q, HE K M, GIRSHICK R, SUN J. Faster r-cnn: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. DOI:10.1109/TPAMI.2016.2577031 |
| [33] |
ZHENG S X, LU J C, ZHAO H S, ZHU X T, LUO Z K, WANG Y B, FU Y W, FENG J F, XIANG T, TORR P H. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition[C]. IEEE, Online, 2021: 6881-6890.
|
(责任编辑 崔建勋)