 2022, Vol. 49
2022, Vol. 49文章信息
引用本文 |

基金项目
- 云南省教育厅科学基金(2019J0171);云南农业大学博士科研启动基金(A2032002507)
作者简介
- 刘振洋(1998—),男,在读硕士生,研究方向为数据挖掘、农作物产量预测,E-mail:624041297@qq.com.
通讯作者
- 赵家松(1975—),男,博士,副教授,研究方向为数据挖掘、人工智能与农业应用,E-mail:28740826@qq.com.
文章历史
- 收稿日期:2022-08-25

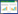


【研究意义】甘蔗产业是云南省特色产业之一,更是扶贫产业之一,云南甘蔗种植面积、产量和产糖量均居全国第二位,仅次于广西,云南省16个地州中有10个地州产糖,主要集中在临沧、德宏、保山、普洱、文山、西双版纳、玉溪、红河8个地州、市、县,全省129个县(市)中有52个县(市、区)种植甘蔗,多为沿边少数民族地区。对云南省甘蔗产量的研究既有助于云南省特色产业的发展,也可对边区经济发展起到推动作用[1]。产量预测模型是当前产量研究的重要方法之一,通过预测农作物的产量,有助于农作物的种植规划和市场调控。目前主要的产量预测模型有BP神经网络、支持向量机、Cart回归树、线性回归等,这些模型在产量预测方面的应用均较为成熟。
【前人研究进展】BP神经网络模型在产量预测方向的使用最为广泛。彭秋连等[2]、许鑫等[3]将BP神经网络模型应用于农作物产量预测上,其相对误差始终维持较低水平;李修华等[4]使用遗传算法对BP神经网络进行了改进,创新性地采用基于遗传算法的BP神经网络模型对甘蔗产量进行预测,其相对误差和决定系数相对于BP神经网络模型,都有了较大改进。此外,胡程磊等[5]、张浩等[6]提出基于BP神经网络的IPSO-BP神经网络模型和AIGA-BP神经网络模型,在粮食产量预测方向上的预测精度维持在一个较高水平,对比BP神经网络模型也有极大的提升。
支持向量机作为当前机器学习的主流算法,也被大量应用于产量预测研究,段东瑶等[7]将SVM模型使用于绿茶加工含水量变化预测,模型预测精度较高,拟合度较好,具有很强的参考价值;赵桂芝等[8]、施瑶等[9]提出基于PSO算法优化的SVM模型和基于SAFA算法优化的LSSVM模型,为粮食产量预测提供了新的途径。Cart回归树作为数据挖掘的经典算法,也可以被用于产量预测方向,陈湘芳等[10]使用Cart回归树对黄瓜产量进行预测,预测模型的误差较小且具有良好的准确性。灰色模型也被常用于产量预测,余永松等[11]、张永强等[12]使用灰色模型对蔬菜和花生产量进行预测,其模型收敛速度较快且相对误差较小;乔松珊等[13]还将马尔科夫链用于提高灰色模型的精度,对肉类产量进行了很好的预测。
基于其简洁和稳定的特点,线性回归也是产量预测方面使用较为广泛的算法之一。研究表明,将多元线性回归算法用于国内外多种农作物的产量预测,利用多元线性回归算法构建的模型在经济作物和粮食作物的产量预测上,都保持较低的误差和较高的拟合度,证明了线性回归算法在产量预测领域的可行性和实用性[14-20]。关联规则算法作为数据挖掘的重要算法之一,在农业数据分析上同样取得很好的成果。徐霖[21]将关联规则算法应用于土壤肥力评价系统中,计算分析得到土壤肥力与农作物产量之间的关联关系。Santosh等[22]使用关联规则中的Apriori算法,开发出一套基于消费者数据和生产者的农业推荐系统,为农业生产者购买生产资料提供推荐,降低生产风险;Hira等[23]使用关联规则算法建立多维模型,对农业种植中的各农业参数之间的关系进行分析,最终得到多条关联性较强的规则,为农业种植提供指导作用;Niketa等[24]发现多种关联规则算法在农业中的应用,主要用于阐明不同气候与作物生产之间的隐藏模式和关联、农业害虫控制等;Inam等[25]使用关联规则发现多条水稻产量最高水平的强过滤关联规则,对神经网络算法进行优化,建立神经网络模型对水稻产量进行预测。可见,对于农业数据的分析,关联规则法具有很强的可行性和优越性。
【本研究切入点】从以上研究可以发现,线性回归算法被广泛应用于产量预测模型构建,模型将产量作为样本输出,通过输入多个样本特征对产量进行预测。而关联规则算法对农业数据分析的应用可以被用于选择样本特征,选择关联性较强的因素作为样本特征,可以提高产量预测模型的准确性。【拟解决的关键问题】构建基于关联规则和多元线性回归的甘蔗产量预测模型,为云南甘蔗糖业的发展提供科学依据。
1 材料与方法 1.1 数据来源本研究所用数据来自于云南统计年鉴中5个甘蔗主产区(普洱、临沧、文山、红河、德宏)2008—2020年的甘蔗产量、种植条件以及气象条件数据,其中种植条件包括水库数、氮肥用量、磷肥用量、钾肥用量、复合肥用量、地膜使用量、甘蔗种植面积,气象条件包括年均气温和年降水量。以2008—2018年的数据作为训练集,用于模型的训练;以2019—2020年的数据作为测试集,用于测试模型精度,以红河为例,具体原始数据见表 1。
|
1.2 数据预处理
收集数据的过程中往往会出现数据缺失或脏数据的情况,如果不加以处理,将会影响最终预测模型的精度。云南统计年鉴缺少2008—2011年各地州平均气温和年降水量的数据,出现数据缺失的情况。针对这种情况,本研究采用均值填充缺失值的预处理方法,即用2012—2018年各地州平均气温和年降水量的数据取平均值对缺失数据进行补全,并对不同年份相同因素所使用的统计单位进行统一化,保证训练集数据的精确度。
1.3 模型构建1.3.1 模型算法 数据挖掘的意义在于从大量数据中通过算法搜索其中隐藏的信息,将有价值的信息总结为知识。数据挖掘的主要方法包括关联规则、决策树、线性回归、神经网络等,本研究主要采用关联规则和线性回归构建预测模型,具体算法则采用Apriori和多元线性回归算法。
Apriori算法基于其简便性和可靠性,已经成为关联规则中使用范围最广的算法,被广泛应用于规则的挖掘和知识的发现。选用Apriori算法可以对不同因素与甘蔗产量的关联性进行分析,从中找出甘蔗产量的强关联因素,由于在模型的实际构建中,弱关联因素和无关联因素会导致模型的精度下降和关联性降低,因此保留强关联因素作为构建预测模型的样本特征,同时舍弃弱关联和无关联因素。
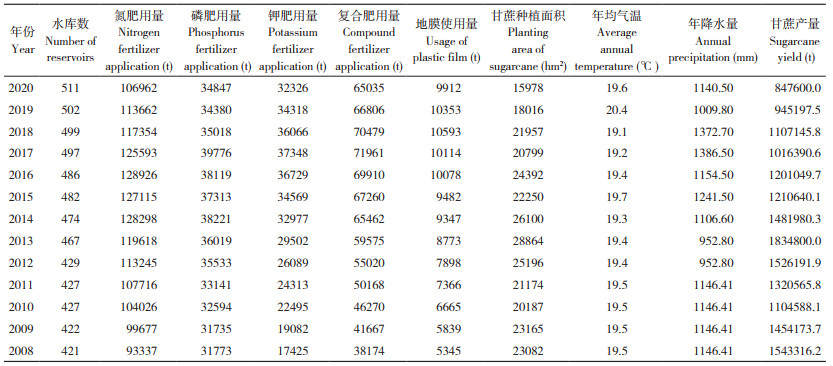
多元线性回归算法是当前使用最为广泛的线性回归算法之一,该算法在产量预测中应用十分广泛。多元线性回归算法可以表示多个样本特征与样本输出之间的线性关系,其一般形式表示为:
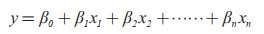
|
式中,y为样本输出,x1,x2, ⋯⋯xn为n个样本特征,β0为常数,β1,β2, ⋯⋯βn为回归系数。
多元线性回归算法可以通过输入多个样本特征得到相应的样本输出,从而达到预测目的,因此采用多元线性回归算法构建产量预测模型。在得到甘蔗产量的强关联因素后,以甘蔗产量的强关联因素作为多元线性回归的样本特征,构建多元线性回归模型。
1.3.2 甘蔗产量影响因素分析 由于Apriori算法需要的数据格式是二元的,所以首先需要对数据进行二元化处理,转化为Apriori算法需要的数据格式。数据处理方法为分别将每个地区2008—2017年的数据转化为10×10阶的矩阵S1,2009—2018年的数据以同样的方式转化为10×10阶的矩阵S2,将S2与S1进行比较,对应位置的数据同比上升的记录为1,同比未上升的记录为0,转化结果为新的10×10阶矩阵S3。以临沧市的甘蔗种植条件、气象条件数据及甘蔗产量数据为例,具体转化过程如图 1所示。

|
| 图 1 矩阵转化过程 Fig. 1 Matrix transformation process |
在得到每个地区的S3后,将所有5个地区的S3合并为一个50×10阶矩阵,记作S4,使用Apriori算法对S4进行分析,计算每个影响因素对甘蔗产量的支持度、置信度、提升度,结果如表 2所示。
1.3.3 多元线性回归预测模型构建 关联规则是形如A=>B的蕴含式,其中A称为规则前件,B称为规则后件。通常用支持度和置信度作为关联规则的价值度量,其中支持度反映A与B同时出现的概率,揭示规则的有用性;置信度反映A出现时B也出现的可能性大小,揭示规则的可靠性。同时满足最小支持度阈值(min_sup)和最小置信度阈值(min_conf)的规则称为强关联规则,本研究设置min_sup=0.4、min_conf=0.5。由表 2可知,包括种植因素和气候因素在内,甘蔗产量的影响因素共有9个,其中年均气温与年降水量两个因素对甘蔗产量的支持度和置信度分别小于0.4和0.5,因此年均气温与年降水量两个因素对于甘蔗产量而言是弱关联因素。
此外,考虑到置信度忽略了规则后件中项集的支持度,引入规则的提升度有助于解决这个问题。规则的提升度可以有效判断规则是否有实际价值,如果A=>B的提升度大于1,则说明A和B正相关。表 1中水库数、复合肥用量两个因素对甘蔗产量的提升度小于1,这两个因素也作为弱关联因素。
根据上述数据分析,基于关联规则方法,将甘蔗产量的影响因素由9个缩减为5个,使用氮肥用量、磷肥用量、钾肥用量、地膜使用量、甘蔗种植面积5个与甘蔗产量正相关的强关联因素作为多元线性回归模型的样本特征,构建多元线性回归模型,具体模型如下式所示:
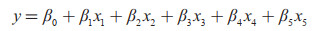
|
式中,y为甘蔗产量,x1,x2,⋯⋯x5分别为氮肥用量、磷肥用量、钾肥用量、地膜使用量、甘蔗种植面积,β0为常数项,β1,β2,⋯⋯β5分别为对应样本特征的回归系数。将5个样本特征的训练集数据代入模型进行训练,可以得到不同地区预测模型的回归系数和β0,以回归系数和β0构建多元线性回归模型,作为最终的甘蔗产量预测模型。
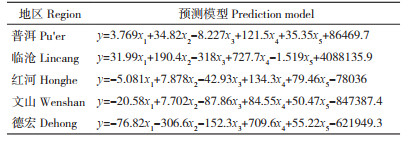
2 结果与分析 2.1 模型构建结果将Apriori算法分析出的5个强关联因素作为样本特征,并设置甘蔗产量为目标变量(样本输出),可以得到云南省各地州的多元线性回归预测模型。通过代入回归系数及β0,各地州甘蔗产量预测模型如表 3所示。
2.2 模型测试与评判
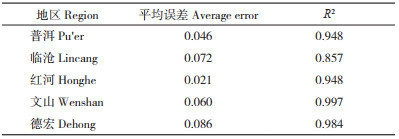
R2是评判多元线性回归模型的重要标准之一,在多元线性回归模型中,R2代表着多元线性回归模型的拟合程度,R2越接近1,模型的拟合程度越好。此外,平均误差也是评判模型精准度的重要指标,将测试集数据代入各地州甘蔗产量预测模型后,可以计算出预测模型的平均误差。由表 4可知,各地州甘蔗产量预测模型的平均误差处于2.1%~8.6% 之间,R2处于0.857~0.997之间,表明各地州甘蔗产量预测模型的平均误差较小、拟合程度较好,该模型具有较好的参考性和研究价值。
2.3 模型对比
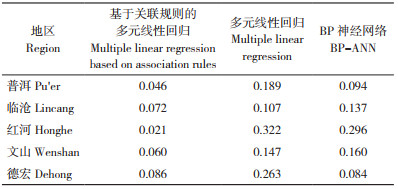
BP神经网络模型作为产量预测领域使用最为广泛的模型,在产量预测方面有许多应用,通过与其对比可以说明基于关联规则的多元线性回归模型在预测精度上的优劣势,分别构建BP神经网络模型和多元线性回归模型,代入测试集数据对甘蔗产量进行预测用于计算平均误差,并将两种预测模型的平均误差与基于关联规则的多元线性回归模型的平均误差进行对比分析。取9个样本特征,代入训练集数据构建两种预测模型,并分别对两种预测模型依次代入测试集数据进行验证。
在使用相同样本特征的情况下,基于关联规则的多元线性回归模型的平均误差在2.1%~8.6% 之间,而多元线性回归模型的平均误差在10.7%~32.2% 之间,BP神经网络模型的平均误差则在8.4%~29.6% 之间,具体对比结果如表 5所示。
3 实证分析
为验证模型的可靠性与实用性,将2019年云南省5个甘蔗主产区(普洱、临沧、文山、红河、德宏)的甘蔗种植条件数据以及气象条件数据代入模型,获得模型的预测产量,并与实际的甘蔗产量数据进行对比,计算相对误差,结果(表 6)表明,模型预测产量和实际的甘蔗产量较为接近,相对误差较小,具有较强的可靠性和实用性。
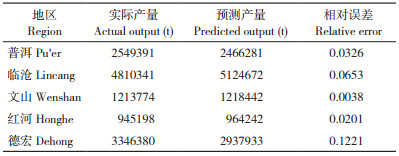
|
4 讨论
得益于数据挖掘和人工智能技术的蓬勃发展,农业生产中产生的大量数据得到充分的挖掘和利用,以产量预测为例,其中获得的知识被反作用于农业生产,让农业生产逐步迈入数据时代。前人研究表明,在目前国内外产量预测领域,线性回归、BP神经网络、支持向量机、Cart回归树等算法具有大量的应用成果。但随着样本特征的增加和种植环境的复杂化,产量预测模型的拟合度会出现下降趋势,Niazian等[26]使用多元线性回归算法构建预测模型,对阿朱万种子产量进行预测,其模型训练集R2为0.81、测试集R2为0.79。Abdipoura等[27]使用多元线性回归算法对红花种子产量进行预测,其模型训练集R2 = 0.71、测试集R2 = 0.686。针对这种情况,许多学者采用优化算法对基础模型进行优化从而提高模型的准确率,如遗传算法、IPSO算法对BP神经网络的优化,PSO算法和SAFA算法对SVM的优化,均大大提高了模型的准确率和拟合度。本研究基于前人优化模型理念,利用关联规则算法对样本特征和样本输出之间的关联性进行分析,筛选出强关联的样本特征,对多元线性回归算法进行优化,降低复杂环境和多个样本特征对多元线性回归算法的影响,在相同条件下提高了多元线性回归算法的准确率和拟合度。
与其他类型的产量预测模型类似,本研究所提出的甘蔗产量预测模型在地域和时效上存在一定的局限性。对云南省甘蔗主产区以外的地区,模型的准确率和拟合度不能得到保证,而且随着时间的推移和种植数据的不断增加,模型的准确率也会发生变化。为获取更精准的预测效果,需要考虑将未来产生的甘蔗产量数据、种植条件数据以及气象条件数据加入训练集,对模型进行更新训练,保证模型的可靠性与时效性。
5 结论本研究构建基于关联规则算法的多元线性回归模型,根据测试集的测试结果可以看出,该模型精度在91%~97% 之间,R2在0.857~0.997,表明基于关联规则的多元线性回归模型具有较高的预测精度和拟合度,预测结果较为准确,为甘蔗产量预测模型提供了新的方法。由于使用的数据集皆为云南统计年鉴的真实数据,因此该模型具有一定的应用价值,可以被用于云南省的甘蔗产量研究。同时,该模型表明关联规则算法对多元线性回归算法的改进作用,可为后续的产量预测模型提供新的改进思路。
| [1] |
邓军, 武晋宇, 朱建荣, 杨绍林, 樊仙. 2018年云南甘蔗产业损害监测预警分析[J]. 中国糖料, 2018, 40(6): 77-80. DOI:10.13570/j.cnki.scc.2018.06.023 DENG J, WU J Y, ZHU J R, YANG S L, FAN X. Early warning analysis of sugarcane industry damage monitoring in Yunnan in 2018[J]. Sugar Crops of China, 2018, 40(6): 77-80. DOI:10.13570/j.cnki.scc.2018.06.023 |
| [2] |
彭秋连, 冯璐, 邓军, 樊仙, 张跃彬. BP神经网络在云南甘蔗产量预测中的应用[J]. 中国糖料, 2019, 41(3): 54-57. DOI:10.13570/j.cnki.scc.2019.03.011 PENG Q L, FENG L, DENG J, FAN X, ZHANG Y B. Application of BP neural network in predication of sugarcane yield in Yunnan Province[J]. Sugar Crops of China, 2019, 41(3): 54-57. DOI:10.13570/j.cnki.scc.2019.03.011 |
| [3] |
许鑫, 马兆务, 熊淑萍, 马新明, 程涛, 李海洋, 赵锦鹏. 基于气候年型的河南省冬小麦产量预测[J]. 中国农业科技导报, 2022, 24(2): 136-144. DOI:10.13304/j.nykjdb.2020.0886 XU X, MA Z W, XIONG S P, MA X M, CHENG T, LI H Y, ZHAO J P. Wheat yield forecast in Henan Province based on climate year type[J]. Journal of Agricultural Science and Technology, 2022, 24(2): 136-144. DOI:10.13304/j.nykjdb.2020.0886 |
| [4] |
李修华, 李婉, 张木清, 温标堂, 叶志鹏, 张云皓. 基于田间环境及气象数据的甘蔗产量预测方法[J]. 农业机械学报, 2019, 50(S1): 233-236. DOI:10.6041/j.issn.1000-1298.2019.S0.036 LI X H, LI W, ZHANG M Q, WEN B T, YE Z P, ZHANG Y H. Sugarcane yield prediction method based on field environmental and meteorological data[J]. Transactions of the Chinese Society for Agricultural Machinery, 2019, 50(S1): 233-236. DOI:10.6041/j.issn.1000-1298.2019.S0.036 |
| [5] |
胡程磊, 刘永华, 高菊玲. 基于IPSO-BP模型的粮食产量预测方法研究[J]. 中国农机化学报, 2021, 42(3): 136-141. DOI:10.13733/j.jcam.issn.2095-5553.2021.03.019 HU C L, LIU Y H, GAO J L. Research on prediction method of grain yield based on ISPO-BP model[J]. Journal of China Agricultural Mechanization, 2021, 42(3): 136-141. DOI:10.13733/j.jcam.issn.2095-5553.2021.03.019 |
| [6] |
张浩, 王国伟, 苑超, 胡红艳. 基于AIGA-BP神经网络的粮食产量预测研究[J]. 中国农机化学报, 2016, 37(6): 205-209. DOI:10.13733/j.jcam.issn.2095-5553.2016.06.45 ZHANG H, WANG G W, YUAN C, HU H Y. Research on forecast of grain production based on AIGP-BP neural net work[J]. Journal of China Agricultural Mechanization, 2016, 37(6): 205-209. DOI:10.13733/j.jcam.issn.2095-5553.2016.06.45 |
| [7] |
段东瑶, 赵丽清, 殷元元, 郑映晖, 徐鑫, 孙颖. 绿茶加工过程含水率变化规律及预测模型研究[J]. 中国农机化学报, 2022, 43(3): 75-83. DOI:10.13733/j.jcam.issn.2095-5553.2022.03.010 DUAN D Y, ZHAO L Q, YIN Y Y, ZHENG Y H, XU X, SUN Y. Research on the law of moisture change andprediction model in the process of green tea[J]. Journal of China Agricultural Mechanization, 2022, 43(3): 75-83. DOI:10.13733/j.jcam.issn.2095-5553.2022.03.010 |
| [8] |
赵桂芝, 赵华洋, 李理, 刘光宇. 基于混沌-SVM-PSO的粮食产量预测方法研究[J]. 中国农机化学报, 2019, 40(1): 179-183. DOI:10.13733/j.jcam.issn.2095-5553.2019.01.33 ZHAO G Z, ZHAO H Y, LI L, LIU G Y. Study on method for food yield prediction based on chaotic theory-SVM-PSO[J]. Journal of China Agricultural Mechanization, 2019, 40(1): 179-183. DOI:10.13733/j.jcam.issn.2095-5553.2019.01.33 |
| [9] |
施瑶, 陈昭. 基于SAFA优化LSSVM的粮食产量预测[J]. 中国农机化学报, 2019, 40(3): 144-148. DOI:10.13733/j.jcam.issn.2095-5553.2019.03.26 SHI Y, CHEN Z. Prediction of grain yield based on LSSVM optimized by SAFA[J]. Journal of China Agricultural Mechanization, 2019, 40(3): 144-148. DOI:10.13733/j.jcam.issn.2095-5553.2019.03.26 |
| [10] |
陈湘芳, 陈明, 冯国富, 池涛. 多变量时序回归树的黄瓜产量预测模型[J]. 计算机工程与设计, 2012, 33(1): 407-411. DOI:10.16208/j.issn1000-7024.2012.01.012 CHEN X F, CHEN M, FENG G F, CHI T. Yield prediction model of cumumber of based on multivariate time seriesreg ression tree[J]. Computer Engineering and Design, 2012, 33(1): 407-411. DOI:10.16208/j.issn1000-7024.2012.01.012 |
| [11] |
余永松, 庞正武, 周叶宁, 钟文峰, 何龙飞, 王爱勤. 广西蔬菜产量灰色预测模型GM(1, 1) 的建立及其相关性分析[J]. 广东农业科学, 2018, 45(7): 157-164. DOI:10.16768/j.issn.1004-874X.2018.07.025 YU Y S, PANG Z W, ZHOU Y N, ZHONG W F, HE L F, WANG A Q. Forecast and suggestion of vegetable production in Guangxi based on Gray Prediction Model GM(1.1)[J]. Guangdong Agricultural Sciences, 2018, 45(7): 157-164. DOI:10.16768/j.issn.1004-874X.2018.07.025 |
| [12] |
张永强, 才正, 王刚毅. 山东省花生年产量的组合预测模型研究[J]. 广东农业科学, 2014, 41(21): 11-15, 21. DOI:10.16768/j.issn.1004-874X.2014.21.019 ZZHANG Y Q, CAI Z, WANG G Y. Combined predictive model research of annual production of peanut in Shandong province[J]. Guangdong Agricultural Sciences, 2014, 41(21): 11-15, 21. DOI:10.16768/j.issn.1004-874X.2014.21.019 |
| [13] |
乔松珊, 张建军. 加权马尔可夫链理论在肉类产量预测中的应用[J]. 广东农业科学, 2013, 40(15): 218-220, 224. DOI:10.16768/j.issn.1004-874X.2013.15.001 QIAO S S, ZHANG J J. Application of weighted Markov theory in meat yield prediction[J]. Guangdong Agricultural Sciences, 2013, 40(15): 218-220, 224. DOI:10.16768/j.issn.1004-874X.2013.15.001 |
| [14] |
黄凯, 查元源, 史良胜. 基于多源数据回归分析的糖料蔗产量估计[J]. 节水灌溉, 2020(6): 24-28. DOI:10.3969/j.issn.1007-4929.2020.06.005 HUANG K, ZHA Y Y, SHI L S. Estimation of sugarcane yield based on regression analysis of multi-source data[J]. Water Saving Irrigation, 2020(6): 24-28. DOI:10.3969/j.issn.1007-4929.2020.06.005 |
| [15] |
FU H, WANG C, GUI G, SHE W, ZHAO L. Ramie yield estimation based on UAV RGB images[Z]. Sensors, 2021: 21. DOI: 10.3390/s21020669.
|
| [16] |
DAS B, NAIR B, REDDY V K, VENKATESH P. Evaluation of multiple linear, neural network and penalised regression models for prediction of rice yield based on weather parameters for west coast of India[J]. International Journal of Biometeorology, 2018, 62(10): 1809-1822. DOI:10.1007/s00484-018-1583-6 |
| [17] |
MORAES J, ROLIM G, MARTORANO L, APARECIDO L E, OLIVEIRA M D S, NETO J. Agrometeorological models to forecast açaí (Euterpe oleracea Mart.) yield in the Eastern Amazon[J]. Journal of the Science of Food and Agriculture, 2020, 100: 1558-1569. DOI:10.1002/jsfa.10164 |
| [18] |
JOSHI V R, KAZULA M J, COULTER J A, NAEVE S L, GARCIA Y G A. In-season weather data provide reliable yield estimates of maize and soybean in the US central corn belt[J]. International Journal of Biometeorology, 2021, 65(4): 489-502. DOI:10.1007/s00484-020-02039-z |
| [19] |
ABROUGUI K, GABSI K, MERCATORIS B T, KHEMIS C, AMAMI R, CHEHAIBI S. Prediction of organic potato yield using tillage systems and soil properties by artificial neural network (ANN) and multiple linear regressions (MLR)[J]. Soil and Tillage Research, 2019(1): 202-208. DOI:10.1016/j.still.2019.01.011 |
| [20] |
GHOLIZADEH A, KHODADADI M, SHARIFI-ZAGHEH A. Modeling the final fruit yield of coriander (Coriandrum sativum L.) using multiple linear regression and artificial neural network models[J]. Archives of Agronomy and Soil Science, 2021, 67: 1894637. DOI:10.1080/03650340.2021.1894637 |
| [21] |
徐霖. 智能数据挖掘技术在土壤肥力评价中的应用[J]. 农机化研究, 2022, 44(12): 225-229. DOI:10.13427/j.cnki.njyi.2022.12.019 XU L. Application of intelligent data mining technology in soil fertility evaluation[J]. Journal of Agricultural Mechanization Research, 2022, 44(12): 225-229. DOI:10.13427/j.cnki.njyi.2022.12.019 |
| [22] |
SANTOSH KUMAR M B, BALAKRISHNAN K. Development of a model recommender system for agriculture using apriori algorithm[C]. Singapore: Springer Singapore, 2019. DOI: 10.1007/978-981-13-0617-4_15.
|
| [23] |
HIRA S, DESHPANDE P S. Data analysis using multidimensional modeling, statistical analysis and data mining on agriculture parameters[J]. Procedia Computer Science, 2015(6): 431-439. DOI:10.1016/j.procs.2015.06.050 |
| [24] |
NIKETA G, LEISA J A. A review of the application of data mining techniques for decision making in agriculture//2016 2nd International Conference on Contemporary Computing and Informatics (IC3I)[C]. 2016. DOI: 10.1109/IC3I.2016.7917925.
|
| [25] |
INAM A, SUPRO. Rice yield prediction and optimization using association rules and neural network methods to enhance agribusiness[J]. Indian Journal of Science and Technology, 2020(13): 1367-1379. DOI:10.17485/IJST/V13I13.79 |
| [26] |
NIAZIAN M, SADAT-NOORI S A, ABDIPOUR M. Modeling the seed yield of Ajowan (Trachyspermum ammi L.) using artificial neural network and multiple linear regression models[J]. Industrial Crops and Products, 2018, 3: 224-234. DOI:10.1016/j.indcrop.2018.03.013 |
| [27] |
ABDIPOUR M, YOUNESSI-HMAZEKHANLU M, RAMAZANI S H R, OMIDI A H. Artificial neural networks and multiple linear regression as potential methods for modeling seed yield of safflower (Carthamus tinctorius L.)[J]. Industrial Crops and Products, 2019, 127: 185-194. DOI:10.1016/j.indcrop.2018.10.050 |
(责任编辑 邹移光)